require(Rdistance)Loading required package: RdistanceLoading required package: unitsudunits database from C:/Users/trent/AppData/Local/R/win-library/4.4/units/share/udunits/udunits2.xmlRdistance (v4.0.3)
This tutorial is a beginner’s guide to doing point transect distance-sampling analysis using Rdistance. Topics covered include input data requirements, fitting a detection function, estimating abundance (or density), and selecting the best fit detection function using AICc. We use the internal datasets thrasherDetectionData and thrasherSiteData (point transect surveys of brown thrashers). This tutorial is current as of version 4.0.3 of Rdistance.
If you haven’t already done so, install the latest version of Rdistance. In the R console, issue install.packages("Rdistance"). After the package is installed, it can be loaded into the current session as follows:
require(Rdistance)Loading required package: RdistanceLoading required package: unitsudunits database from C:/Users/trent/AppData/Local/R/win-library/4.4/units/share/udunits/udunits2.xmlRdistance (v4.0.3)For this tutorial, we use two datasets collected by J. Carlisle on brown thrashers in central Wyoming that are included with Rdistance.
The first dataset, thrasherDetectionData, is a detection data.frame with one row for each detected object. Columns in the data frame are:
siteID = Factor, the site (point) and transect surveyed. Levels are five character codes like ‘TTXPP’ where TT is transect number and PP is the point within the transect.groupsize = Numeric, the number of individuals within the detected group.dist = Numeric, the radial distance from the point to the detected group. Obtain access to the example dataset of thrasher detections and observed distances (thrasherDetectionData) using the following commands:data("thrasherDetectionData")
head(thrasherDetectionData) siteID groupsize dist
1 C1X01 1 11 [m]
2 C1X01 1 183 [m]
3 C1X02 1 58 [m]
4 C1X04 1 89 [m]
5 C1X05 1 83 [m]
6 C1X06 1 95 [m]The second required dataset, thrasherSiteData, is a transect data.frame, with one row for each transect surveyed, and the following required columns:
siteID = Factor, the site (point) and transect surveyed.... = Any additional transect-level covariate columns (these will not be used in this tutorial).Load the example dataset of thrasher transects (thrasherSiteData) using the following commands:
data("thrasherSiteData")
head(thrasherSiteData) siteID observer bare herb shrub height npoints
1 C1X01 obs5 45.8 19.5 18.7 23.7 1
2 C1X02 obs5 43.4 20.2 20.0 23.6 1
3 C1X03 obs5 44.1 18.8 19.4 23.7 1
4 C1X04 obs5 38.3 22.5 23.5 34.3 1
5 C1X05 obs5 41.5 20.5 20.6 26.8 1
6 C1X06 obs5 43.7 18.6 20.0 23.8 1The final step in data preparation is to make an ‘Rdistance data frame’. ‘Rdistance data frames’ are nested data frames that contain site and detection information in one object. To do this, execute the ‘Rdistance data frame’ constructor function RdistDf, making sure to set pointSurvey to TRUE and specifying which column in thrasherSiteData contains the number of points on each transect.
thrasherDf <- RdistDf(thrasherSiteData
, thrasherDetectionData
, by = "siteID"
, pointSurvey = TRUE
, .effortCol = "npoints")The summary method provides a final check of the data.
summary(thrasherDf, formula = dist ~ groupsize(groupsize))Transect type: point
Effort:
Transects: 120
Total length: 120 [points]
Distances:
0 [m] to 265 [m]: 193
Sightings:
Groups: 193
Individuals: 196 Once the data are imported, the first step is to fit a detection function. Before we do so, explore the distribution of the distances:
hist(unnest(thrasherDf)$dist, n=40, col="grey", main="", xlab="distance (m)")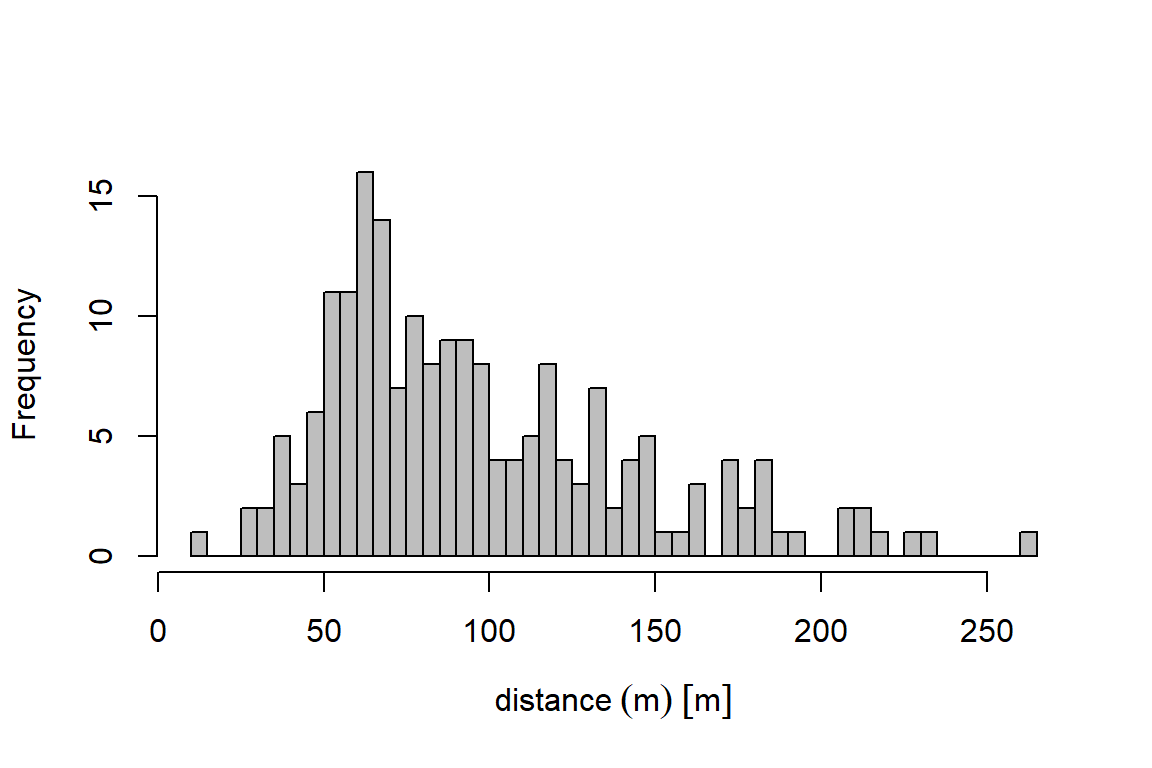
summary(unnest(thrasherDf)$dist) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
11.00 63.00 86.00 97.16 123.00 265.00 2 Next, we fit a detection function using dfuncEstim to the radial distances collected from the point transects and plot it. We specify the half-normal distance function using option likelihood = "halfnorm". In section 5, we demonstrate an automated process to fit multiple detection functions and compare them using AICc.
dfunc <- dfuncEstim(thrasherDf
, formula = dist ~ groupsize(groupsize)
, likelihood = "halfnorm")
plot(dfunc)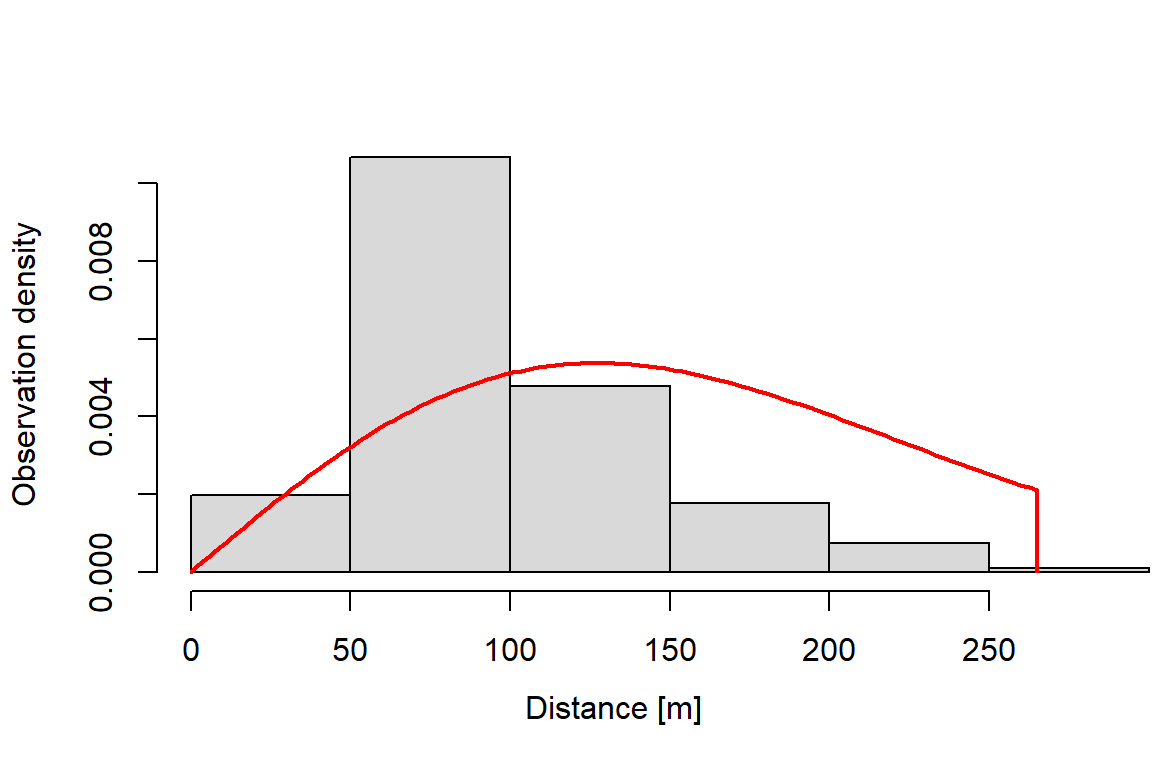
summary(dfunc)Call: dfuncEstim(data = thrasherDf, formula = dist ~
groupsize(groupsize), likelihood = "halfnorm")
Coefficients:
Estimate SE z p(>|z|)
(Intercept) 4.844148 0.09047851 53.53921 0
Convergence: Success
Function: HALFNORM
Strip: 0 [m] to 265 [m]
Effective detection radius (EDR): 169.112 [m]
Probability of detection: 0.4072462
Scaling: g(0 [m]) = 1
Log likelihood: -1059.836
AICc: 2121.692The effective detection radius (EDR) is the essential information from the detection function that will be used to estimate abundance in section 4. The EDR is calculated by integrating the detection function to compute area under the detection function. See the help documentation for EDR for details.
Estimating abundance requires the additional information contained in the the thrasher site dataset, described in section 2, where each row represents one transect. Load the example dataset of surveyed thrasher transects from the package.
We estimate abundance (or density in this case) using abundEstim. If we do not specify a study area size, density is given in the squared units of the distance measurements — in this case, thrashers per square meter. If we set area = 1 hectare (1 ha == 10,000 m^2), both density per square meter and density per hectare will be given. The equation used to calculate the abundance estimate is detailed in the help documentation for abundEstim.
Confidence intervals for abundance are calculated using a bias-corrected bootstrapping method (see abundEstim). Note that, as with all bootstrapping procedures, there may be slight differences in the confidence intervals between runs. Increasing the number of bootstrap iterations (R = 100 used here for brevity) may be necessary to stabilize CI estimates.
# Estimate Abundance - Density; fatalities per m2
fit <- abundEstim(object = dfunc
, area = units::set_units(1, "ha") # density per hectare
, R = 100
, ci = 0.95)summary(fit)Call: dfuncEstim(data = thrasherDf, formula = dist ~
groupsize(groupsize), likelihood = "halfnorm")
Coefficients:
Estimate SE z p(>|z|)
(Intercept) 4.844148 0.09047851 53.53921 0
Convergence: Success
Function: HALFNORM
Strip: 0 [m] to 265 [m]
Effective detection radius (EDR): 169.112 [m]
Probability of detection: 0.4072462
Scaling: g(0 [m]) = 1
Log likelihood: -1059.836
AICc: 2121.692
Surveyed Units: 120
Individuals seen: 196 in 193 groups
Average group size: 1.015544
Group size range: 1 to 2
Density in sampled area: 1.817926e-05 [1/m^2]
95% CI: 1.417209e-05 [1/m^2] to 2.315951e-05 [1/m^2]
Abundance in 10000 [m^2] study area: 0.1817926
95% CI: 0.1417209 to 0.2315951The abundance estimate can be extracted from the fit object.
data.frame(fit$estimates) id density density_lo density_hi
1 Original 1.817926e-05 [1/m^2] 1.417209e-05 [1/m^2] 2.315951e-05 [1/m^2]
abundance abundance_lo abundance_hi avgEffDistance avgEffDistance_lo
1 0.1817926 0.1417209 0.2315951 169.112 [m] 150.1516 [m]
avgEffDistance_hi X.Intercept. nGroups nSeen area surveyedUnits
1 190.7389 [m] 4.844148 193 196 10000 [m^2] 120
avgGroupSize
1 1.015544Fitting several detection functions, choosing the best fitting, and estimating abundance (sections 3 and 4) can be automated using the function autoDistSamp. The function attempts to fit multiple detection functions, uses AICc (by default, but see help documentation for autoDistSamp under criterion for other options) to find the ‘best’ detection function, then proceeds to estimate abundance using the best fit detection function (the distance function with lowest AICc). By default, autoDistSamp tries a large subset of Rdistance’s built-in detection functions, but you can control exactly which detection functions are attempted (see help documentation for autoDistSamp). Specifying plot=TRUE produces a plot of each detection function as it is estimated. Specifying, plot.bs=TRUE plots the selected distance function each iteration of the bootstrap procedure. In this example, we fit the half-normal, hazard rate, exponential, and uniform likelihoods with no expansion terms, we do not plot all fitted functions (plot=FALSE), but we plot the best distance function fitted during each bootstrap iteration.
# Automated Fit - fit several models, choose the best model based on AIC
autoDS <- autoDistSamp(
data = thrasherDf
, formula = dist ~ groupsize(groupsize)
, likelihoods = c("halfnorm", "hazrate", "negexp")
, plot = FALSE
, area = units::set_units(1, "ha")
, R = 100
, ci = 0.95
, plot.bs = FALSE)Likelihood Series Expans Converged? Scale? AICc
halfnorm cosine 0 Yes Ok 2121.6923
halfnorm cosine 1 No NA NA
halfnorm cosine 2 Yes Not ok NA
halfnorm cosine 3 Yes Not ok NA
hazrate cosine 0 Yes Ok 2075.4534
hazrate cosine 1 No NA NA
hazrate cosine 2 Yes Not ok NA
hazrate cosine 3 Yes Not ok NA
negexp cosine 0 Yes Ok 2155.7967
negexp cosine 1 No NA NA
negexp cosine 2 Yes Not ok NA
negexp cosine 3 Yes Not ok NA
Note: Some models did not converge or had parameters at their boundaries.
------------ Abundance Estimate Based on Top-Ranked Detection Function ------------
Call: Rdistance::dfuncEstim(data = data, formula = formula, likelihood
= fit.table$like[1], w.lo = w.lo, w.hi = w.hi, expansions =
fit.table$expansions[1], series = fit.table$series[1], x.scl = w.lo,
g.x.scl = 1, warn = TRUE, outputUnits = NULL)
Coefficients:
Estimate SE z p(>|z|)
(Intercept) 5.026968 0.05810598 86.513778 0.000000e+00
k 6.203649 1.14700558 5.408561 6.353324e-08
Convergence: Success
Function: HAZRATE
Strip: 0 [m] to 265 [m]
Effective detection radius (EDR): 173.0842 [m]
Probability of detection: 0.4266022
Scaling: g(0 [m]) = 1
Log likelihood: -1035.695
AICc: 2075.453
Surveyed Units: 120
Individuals seen: 196 in 193 groups
Average group size: 1.015544
Group size range: 1 to 2
Density in sampled area: 1.735442e-05 [1/m^2]
95% CI: 1.40517e-05 [1/m^2] to 2.188136e-05 [1/m^2]
Abundance in 10000 [m^2] study area: 0.1735442
95% CI: 0.140517 to 0.2188136The detection function with the lowest AICc value (and thus selected as the ‘best’) is the hazard rate likelihood with 0 cosine expansion terms.
In sections 3 and 4, we fitted a half-normal detection function and used that function to estimate thrasher density. Our estimate was 0.18 thrashers per ha (95% CI = 0.14 to 0.23). In section 5, we used AICc to estimate a better fitting detection function and used it to estimate thrasher density. The thrasher density estimated by the better-fitting model was 0.17 thrashers per ha (95% CI = 0.14 to 0.22). (Note, CI estimates may vary slightly from these due to minor ‘simulation slop’ inherent in bootstrapping methods).